

“O pesadelo da informação insuficiente que fez nossos pais sofrerem foi substituído pelo pesadelo ainda mais terrível da enxurrada de informações que ameaça nos afogar.”
(Bauman, 2011, p.8)
Os experimentos no Large Hadron Colider no CERN (laboratório de física de partículas na Europa) geram 40 terabytes de dados por segundo, mais informação do que pode ser armazenada ou analisada pelas tecnologias atuais (muitos destes dados são simplesmente descartados, dada a incapacidade de armazená-los). Esta informação foi extraída da revista semanal The Economist(2013), na qual é afirmado que exemplos de manuseio de grandes quantidades de informação como este também são encontrados em outros cenários, como nos bancos de dados do Wall-Mart, de tamanho estimado em torno de 2,5 petabytes, o equivalente a 167 vezes o conteúdo dos livros na biblioteca do congresso americano. Estes e outros exemplos mostram como a criação de dados cresceu nos últimos anos. Estima-se que do início da civilização até 2003, a humanidade criou 5 hexabytes de informação; atualmente esse mesmo volume é criado a cada dois dias (VILLELA, 2013).

Esta expansão no que tange à criação de dados é devida principalmente ao avanço da World Wide Web e a facilidade de colaboração on-line entre pessoas geograficamente dispersas, duas das forças planificadoras do mundo apresentadas por Friedman (2006). Por planificação mundial, Friedman se refere à redução de barreiras impostas pela distância, de modo a garantir uma capacidade de colaboração, em escala mundial, aos indivíduos. O avanço da WWW ocasionou também a proliferação das redes sociais e a difusão dos dispositivos móveis como formas de acesso à rede mundial de computadores. A partir de todas essas origens (dispositivos) e meios (internet), são criados e espalhados enormes e variados conjuntos de dados. Este fenômeno de criação e compartilhamento de dados, em grande volume, velocidade e variedade, tornou-se conhecido como Big Data.
O fenômeno Big Data oferece às organizações novas possibilidades de obtenção de importantes informações sobre seus mercados, competidores e seu negócio (VILLELA, 2013). Através do uso de analytics (i. e. ferramentas de análise de dados), estas organizações conseguem acessar, gerenciar e cruzar estes dados à procura de insights de informações contidas neles. Assim, tais organizações podem, por exemplo, conseguir conhecer um possível nicho consumidor emergente, identificar gargalos operacionais a fim de reduzir os custos envolvidos na produção de algum bem ou desempenho de algum serviço.
Olhar para o Futuro

A grande quantidade de dados que circula no mundo tem originado diversas possibilidades. Por exemplo, através do uso de analytics pesquisadores conseguem analisar informações de milhares de pessoas e compreender o comportamento humano a um nível de população (The Economist, 2013). Este tipo de entendimento do comportamento de grupos humanos tem grande valor para as organizações modernas, pois fornece uma nova força motora para seus negócios. Através deste entendimento, podem-se definir melhores estratégias de venda e produção de bens de consumo, de forma a melhorar o desempenho e aumentar a competitividade da organização. Este aumento de desempenho e competitividade representa algumas das formas de geração de valor a partir da informação, valor este que é intangível se comparado a outras forças motrizes dos negócios, como dinheiro e trabalho. Intangível, pois não gera um valor direto para a organização (com dinheiro compra-se matéria prima, com trabalho produzem-se bens e serviços), mas aplicado em conjunto com outros recursos representa uma excelente ferramenta para o mundo dos negócios.
Para coletar toda esta informação, grandes companhias da web, como Facebook e Google, têm criado centros de pesquisa de informação (DRAGLAND, 2013). A vantagem de tais empresas é que seus serviços, por natureza, produzem grandes quantidades de informações sobre o comportamento das pessoas, extraídos das pesquisas que fazem, das páginas que visualizam etc. No entanto, mesmo pesquisadores que não estejam alocados nestas companhias conseguem ter acesso aos dados. Ferramentas como o Wisdom, uma ferramenta de análise de dados sociais de usuários do Facebook, garantem a seus usuários acesso a dados de enormes grupos de indivíduos.

Através da análise destes grupos de indivíduos, as organizações podem prever as ações de seus consumidores. Um exemplo do emprego deste tipo de técnica pode ser observado em um novo tipo de aplicativo de dispositivos móveis (mobile), os aplicativos preditivos (Mit Technology Review, 2013). Tais aplicativos utilizam técnicas de aprendizado de máquina para assimilar comportamentos dos usuários a partir do histórico de outros usuários. Desta forma, estes aplicativos podem parar de esperar que seus usuários solicitem sua ajuda e recomendar, por exemplo, um filme para assistir no cinema ou um livro para ler assim que você entrar em um aplicativo referente a uma destes temas no seu mobile. Um exemplo de aplicativo preditivo é o Google Now, que coleta informações do e-mail e calendário das pessoas para descobrir, por exemplo, onde e quando elas trabalham e fornecer informações sobre o trânsito (Mit Technology Review, 2013). Por enquanto, o Google Now ainda apresenta alguns problemas, como o fornecimento de informações impróprias disparadas em certas ocasiões (como informar o itinerário de ônibus sempre que você passar por uma parada), mas este é um dos aplicativos pioneiros em coletar as informações dos usuários e as utilizar para tornar suas vidas mais fáceis, alega Tom Simonite, membro da equipe da MIT Technology Review.
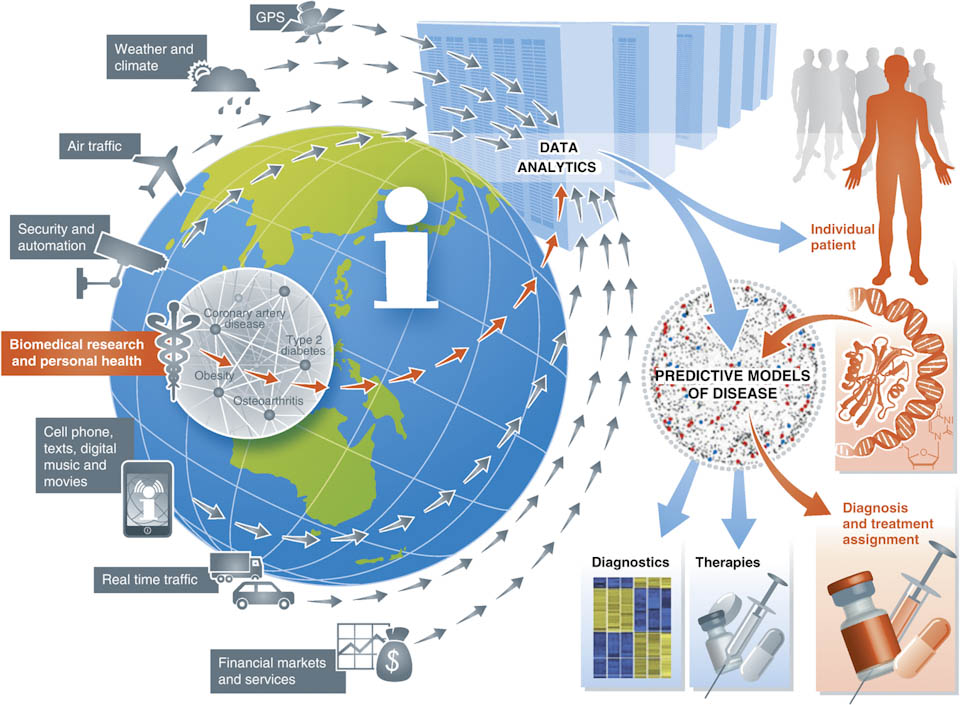
Uma forma de utilizar toda essa informação é através do envio de propagandas (adds) personalizadas para usuários da web. Assim, se você possui tendências de navegar por sites esportivos você provavelmente receberá a oferta de um tênis para praticar esportes, já se você é uma pessoa com hábito de ler artigos científicos, você pode, por exemplo, receber a recomendação de algum curso de pós-graduação. Alguns mecanismos que utilizam essa abordagem de propagandas, como o Google Adds que aparece no Gmail, informam aos usuários o motivo das propagandas aparecerem para ele. Agora imagine um futuro no qual, ao clicar sobre um link que informe o motivo da propaganda aparecer para você seja exibida uma frase do tipo:
“Esta propaganda foi selecionada para você, pois está escrito no seu DNA que…”.

Esta previsão é feita por Susan Young, outro membro da MIT Technology Review. Young diz que em seu DNA podem ser encontradas informações, por exemplo, do padrão masculino de calvície causada por stress, então quem sabe você receba um cartão de desconto para alguma casa de massagem ou SPA. A ideia de tornar publico sua sequência de DNA é justificada pela possível existência de aplicativos médicos que necessitem dessa informação. Porém esta informação, uma vez compartilhada, pode ser utilizada para outros fins. Hoje ainda existem diversos problemas relacionados aos custos de analisar sequências de DNA, no entanto, no futuro tais custos podem reduzir dependendo das tecnologias que surgirão.
Leis nas Transações Virtuais

Atualmente, todo tipo de transação relacionada à informação que os usuários publicam em serviços da internet, ou mesmo em outros lugares, são ditadas por contratos particulares. Desta forma, ao realizar uma compra on-line e começar a receber vários e-mails indesejados, a questão relacionada a violação ou não de alguma regra por parte da loja on-line não será encontrada em nenhum lei ou tribunal, mas sim no contrato firmado entre as partes (HAYNES, 2007), normalmente representado pelos termos de compromisso dos serviços web. A questão é que, mesmo com a crescente preocupação de usuários com sua privacidade, eles não parecem estar muito predispostos a ler estes termos. Além disso, ainda existem questões relacionadas à possibilidade das organizações não estarem lidando com a informação dos seus consumidores como prometem lidar.
Uma vez que os serviços web informam aos seus consumidores sobre o que farão com os dados coletados, e oferecem uma opção de não concordarem com seus termos e consequentemente não usarem o serviço, estes acabam por ter o poder de fazer o que quiserem com os dados dos usuários, desde analisar seus dados até mesmo vendê-los. A forma correta de lidar com estas situações seria o estabelecimento de políticas e leis firmes que protejam a privacidade dos indivíduos. No futuro, tais políticas e leis que permitam aos indivíduos conhecer e controlar a informação sobre eles armazenadas pelas organizações devem ser votadas nos congressos de todo o mundo. Na verdade, segundo Antônio Regalado (Mit Technology Review, 2013) os legisladores californianos introduziram recentemente uma nota à lei Right to Know que requer às companhias que revelem aos indivíduos quais os seus dados estão sendo mantidos armazenados por ela. Esta mesma lei concede aos norte-americanos o direito de conhecerem a quais ele está exposto.
Privacidade

Os analytics são ferramentas em geral utilizadas para analisar grandes conjuntos de dados sobre grupos de pessoas. O poder de análise destas ferramentas aumenta à medida que cresce o número de companhias que as utilizam. Um exemplo da utilização desta informação é apontado no relatório “Data, Data Everywhere” da revista The Economist (2013). O relatório mostra que, na Inglaterra, a Royal Shakespere Company (RSC), uma companhia de teatro clássico, utilizou ferramentas de analytics para filtrar e direcionar suas campanhas de marketing e conseguiu um aumento de 70% dos visitantes. Através da análise das informações dos consumidores foi possível determinar não apenas informações sobre os salários e opiniões deles, mas também dados sobre suas profissões e famílias. Tais informações permitem aos gestores da RSC direcionar mais precisamente suas campanhas de marketing. A questão é o quão precisas podem ser estas análises, e se é possível identificar indivíduos no meio da multidão de perfis analisados.
O recente episódio com o programa de vigilância informática da Agência de Segurança Nacional norte-americana (NSA) mostrou como os indivíduos estão expostos ao utilizarem os mais básicos serviços da internet, como servidores de e-mail e redes sociais. Estes ambientes são propícias bases para coleta de informações por parte das agências do governo ou até mesmo outras organizações. Os usuários da internet gastam muito tempo nestes ambientes e fornecem uma grande quantidade de informações que permite a identificação de seus principais hábitos e comportamentos. Talvez George Orwell tenha acertado sobre o mundo se tornar um grande Big Brother.

Uma das maneiras de proteger-se desse tipo de invasão de privacidade é através dos intitulados “suicídios virtuais”. Estima-se que 11 milhões de pessoas no Reino Unido tenham excluído seus perfis do Facebook após as revelações do programa de vigilância norte-americano (Voice of Russia, 2013). Uma pesquisa no artigo de Stieger, Burger, Bohn & Voracek (2013) aponta as maiores causas para que as pessoas abandonem as redes sociais, mais especificamente o Facebook. A principal causa está relacionada à concepção de privacidade das pessoas, e em segundo lugar seu sentimento de estarem muito vinculadas, ou dependentes, da rede social.

Motivados por esta tendência de suicídio virtual existem hoje diversos tipo de aplicativos que auxiliam as pessoas a apagar seus rastro virtuais, como o justdelete.me. É claro que a porcentagem de usuários que deixam as redes sociais é insignificante dentro do conjunto total de usuários destas redes; nem todos estão dispostos a abandonar sua vida virtual. Além disso, várias ferramentas que facilitam a vida dos usuários utilizam as informações compartilhadas nessas redes, de forma que expor estes dados torna-se inevitável (Mit Technology Review, 2013).
É claro que existem os defensores da análise de todas essas informações, mesmo que isso signifique a redução da privacidade dos usuários. O escritor e filósofo Luiz Felipe Pondé, colunista da Folha de São Paulo, alega que “se alguém é responsável por muitas coisas, nem sempre é possível viver com luvas de pelica”, para justificar as ações do governo norte-americano. Ele diz que ações deste tipo mostram a maturidade do governo americano, que provavelmente vigia outros países, como o Brasil, pois estes estão relacionados a rotas de crimes internacionais e terrorismo. Para o autor, a maturidade do governo americano é contraposta pelo mudo “teenager” que não consegue identificar o que é feito pelo seu próprio bem.
Controle pela Informação

Segundo Greenwald da Mit Technology Review (2013), durante os 18 meses finais da campanha do presidente Obama, um grupo de análise dados coletou e combinou milhares de dados sobre todo o público votante dos Estados Unidos. A partir do resultado desta análise foi possível determinar políticas e campanhas de marketing para influenciar o público mais propício para ir às eleições e votar no atual presidente norte-americano. A aplicação das técnicas de análise de dados apresenta-se como potencialmente decisiva para os resultados da eleição. Episódios como este mostram o poder de influência de organizações que podem analisar o grande volume de dados gerado pelo fenômeno Big Data sobre os indivíduos.
Talvez tal poder de controle da massa através da manipulação desta informação seja apenas mais uma teoria da conspiração propagada com mais força após o surgimento do Big Data. Mesmo assim, campanhas de distração do público de problemas nacionais com assuntos não tão relevantes, como exibir um jogo da seleção brasileira no dia marcado para o maior protesto de rua do país, dão ainda mais força para este tipo de medo. Diversos são os pesquisadores que defendem o uso da análise de informações em massa, e mesmo da manipulação da ação de indivíduos, desde que seja utilizado para o bem da maioria. Através da combinação de informações relacionadas, por exemplo, a formação de gangues, terrorismo, pedofilia, qualidade de vida etc., seria possível que se estabelecessem políticas de combate e campanhas de marketing em prol do bem-estar da população.
É claro que também é assustador um futuro no qual se é manipulado para atingir um estado quase utópico de bem estar e paz. Frequentemente situações assim são utilizadas em histórias de ficção científica, como no livro Eu, Robô (ASIMOV, 1969).

No último conto do livro é narrado um diálogo entre o coordenador mundial Stephen e a psicóloga de robôs Dra. Susan Calvin. Neste diálogo é apresentado como o mundo foi deixado sob o controle das máquinas de forma a tornar-se um lugar no qual “esbanjamento e fome são palavras que só existem nos livros de história” (ASIMOV, 1969, p. 234). Ou ainda como a recente série de animesPSYCHO-PASS, na qual uma nação inteira é governada por uma máquina que tem condições de punir indivíduos apenas a partir de uma análise de seus dados psicológicos, antes mesmo que venham a cometer crimes, apenas baseado na probabilidade latente do indivíduo cometê-lo.

Neste último caso, a partir de uma análise psicológica do indivíduo, o programa de computador conhecido como Sybil Sistem é capaz de identificar até mesmo quais as melhores opções de profissões para os indivíduos daquela nação. Em ambas as histórias, o mundo, ou uma nação específica no segundo caso, conseguem atingir um status de desenvolvimento humano e qualidade de vida sem precedentes, mas permeada por uma sensação estranha de falta de controle por parte dos seres humanos.
Desafios

Junto com as possibilidades trazidas pelo fenômeno Big Data vêm algumas questões que preocupam os indivíduos. Estas questões estão principalmente relacionadas ao controle de toda esta informação. Que tipos de conclusões podem ser obtidas através da análise destes dados? É possível identificar indivíduos específicos na multidão de perfis analisados? Como estes indivíduos devem agir para garantir que seus direitos de privacidade não sejam violados? E como a utilização desinibida destas informações pode afetar a vida das pessoas?
Não é mais somente o detentor dos dados que possui poder, nem tampouco aquele que sabe extrair destes dados as informações que necessita (até porque, parafraseando uma frase corrente no mundo da estatística, “dados torturados confessam qualquer coisa”). Transformar a informação em conhecimento seria a grande questão, se não houvesse uma mais premente: como usar o conhecimento obtido das informações extraídas dos dados com a inteligência e a sabedoria que a humanidade requer para continuar existindo como tal: humana.
Bibliografia
Asimov, I. (1969). Eu , Robô.
Bauman, Z. (2011). 44 cartas do mundo líquido moderno (p. 226). Zahar.
Dragland, A. (2013). Big Data – for better or worse. Retrieved July 01, 2013, from http://www.sintef.no/home/Press-Room/Research-News/Big-Data–for-better-or-worse/
Friedman, T. L. (2006). O Mundo é Plano. OBJETIVA. Retrieved from http://books.google.com.br/books?id=Z_eQp4GyLzYC
Haynes, A. W. (2007). Online Privacy Polices: Contaracting Away Control Over Personal Information. Penn State Law Review, 111, 587–624.
Mit Technology Review. (2013). Big Data Gets Personal (p. 29).
Stieger, S., Burger, C., Bohn, M., & Voracek, M. (2013). Who commits virtual identity suicide? Differences in privacy concerns, internet addiction, and personality between facebook users and quitters. Cyberpsychology, behavior and social networking, 16(9), 629–634. doi:10.1089/cyber.2012.0323
The Economist. (2013). Data, data everywhere. BMJ (Clinical research ed.), 346, f725. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/23381205
Villela, A. (2013). O fenômeno Big Data e seu impacto nos negócios. Retrieved from http://imasters.com.br/gerencia-de-ti/tendencias/o-fenomeno-big-data-e-seu-impacto-nos-negocios/
Voice of Russia. (2013). Facebook “ mass identity suicide ”: 11 million users from US and UK delete their accounts.
Nota: o texto é resultado de uma atividade da disciplina Gestão Tecnológica II, ministrada pela professora Parcilene Fernandes, do curso de Sistemas de Informação do CEULP/ULBRA. Colaboração do Prof. Fabiano Fagundes.
Simplesmente assustador…